Planning
Planner algorithm
The high-level idea
When planning for a query the planner assigns weights to every edge/field, optionally labels them with their batch names (if a batch resolver was used) and finally converts the problem to a simpler DAG (directed asyclic graph) form.
For information on how the planner assigns weights, check out the statistics.
The goal now is to form batches by contracting nodes that are batchable (jobs of the same family in scheduling/OR jargon).
For instance, assume the following DAG is in question:
Now consider the following plan, where a possible contraction is colored red:
And contracted it becomes:
Default planner intuition
The default planner heuristic in gql lazily enumerates all plans, imposing a locally greedy order to the enumerated plans. The default planner also employs some simple but powerful pruning rules to eliminate trivially uninteresting plan variantions.
The planner works through the problem from the root(s) and down through the DAG. The algorithm keeps some state regarding what batches have been visited and what nodes are scheduled in the "current plan". In a round of planning the algorithm will figure out what nodes are schedulable by looking at it's state.
The planner will lazily generate all combinations of possible batches of schedulable nodes.
One can easily cause a combinatorial explosion by generation of combinations. Fortunately we don't consider every plan (and in fact, the default algorithm only pulls plans). Furthermore, most problems will have less than n plans.
The planner will always generate the largest batches first, hence the "locally greedy" ordering.
Trivially schedulable nodes are always scheduled first if possible; a pruning rules makes sure of this. For a given scheduleable node, if no other un-scheduled node exists of the same family (excluding it's own descendants), then that node's only and optimal batch is the singleton batch containing only that node.
There are other pruning rules that have been considered, but don't seem necessary for practical problems since most problems produce very few plans.
One such pruning rule consideres "optimal" generated batch combinations. If the largest batch that the planner can generate contains nodes that all have the same "latest ending parent", then all other combinations are trivially fruitless.
Once the planner has constructed a lazy list of batches, it then consideres every plan that could exist for every batch, hence a computational difficulty of finding the best plan.
If you want to understand the algorithm better, consider taking a look at the source code.
Converting a query to a problem
gql considers only resolvers when running query planning. Every field that is traversed in a query is expanded to all the resolvers it consists such that it becomes a digraph.
As an example, consider the following instance:
import gql._
import gql.dsl.all._
import gql.ast._
import gql.server.planner._
import gql.resolver._
import scala.concurrent.duration._
import cats.implicits._
import cats.effect._
import cats.effect.unsafe.implicits.global
case object Child
def wait[I](ms: Int) = Resolver.effect[IO, I](_ => IO.sleep(50.millis))
val schem = Schema.stateful{
Resolver.batch[IO, Unit, Int](_ => IO.sleep(10.millis) as Map(() -> 42)).flatMap{ b1 =>
Resolver.batch[IO, Unit, String](_ => IO.sleep(15.millis) as Map(() -> "42")).map{ b2 =>
implicit lazy val child: Type[IO, Child.type] = builder[IO, Child.type]{ b =>
b.tpe(
"Child",
"b1" -> b.from(wait(50) andThen b1.opt map (_.get)),
"b2" -> b.from(wait(100) andThen b2.opt map (_.get)),
)
}
SchemaShape.unit[IO](
builder[IO, Unit]{ b =>
b.fields(
"child" -> b.from(wait(42) as Child),
"b2" -> b.from(wait(25) andThen b2.opt map (_.get))
)
}
)
}
}
}.unsafeRunSync()
Now let's define our query and modify our schema so the planner logs:
val qry = """
query {
child {
b1
b2
}
b2
}
"""
val withLoggedPlanner = schem.copy(planner = new Planner[IO] {
def plan(naive: NodeTree): IO[OptimizedDAG] =
schem.planner.plan(naive).map { output =>
println(output.show(ansiColors = false))
println(s"naive: ${output.totalCost}")
println(s"optimized: ${output.optimizedCost}")
output
}
})
And we plan for it inspect the result:
def runQry() = {
Compiler[IO]
.compile(withLoggedPlanner, qry)
.traverse_{ case Application.Query(fa) => fa }
.unsafeRunSync()
}
runQry()
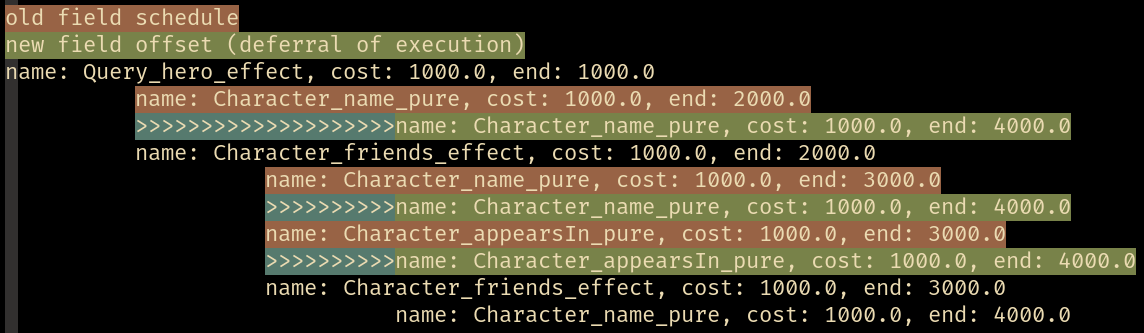
// name: Query_child.compose-left.compose-right.compose-right, cost: 100.00, end: 100.00, batch: 5
// name: Child_b2.compose-left.compose-left.compose-right, cost: 100.00, end: 200.00, batch: 2
// name: batch_1, cost: 100.00, end: 300.00, batch: 4
// name: Child_b1.compose-left.compose-left.compose-right, cost: 100.00, end: 200.00, batch: 3
// name: batch_0, cost: 100.00, end: 300.00, batch: 1
// name: Query_b2.compose-left.compose-left.compose-right, cost: 100.00, end: 100.00, batch: 0
// name: batch_1, cost: 100.00, end: 200.00, batch: 4
// >>>>>>>>>>>>>name: batch_1, cost: 100.00, end: 300.00, batch: 4
//
// naive: 700.0
// optimized: 600.0
We can warm up the weights (statistics) a bit by running the query a few times:
(0 to 10).toList.foreach(_ => runQry())
Now we can see how the weights are assigned:
runQry()
// name: Query_child.compose-left.compose-right.compose-right, cost: 50085.82, end: 50085.82, batch: 4
// name: Child_b2.compose-left.compose-left.compose-right, cost: 50068.64, end: 100154.46, batch: 0
// name: batch_1, cost: 15066.00, end: 115220.46, batch: 1
// name: Child_b1.compose-left.compose-left.compose-right, cost: 50087.00, end: 100172.82, batch: 2
// name: batch_0, cost: 10066.00, end: 110238.82, batch: 3
// name: Query_b2.compose-left.compose-left.compose-right, cost: 50130.64, end: 50130.64, batch: 5
// name: batch_1, cost: 15066.00, end: 65196.64, batch: 1
// >>>>>>>>>>>>>>>>>name: batch_1, cost: 15066.00, end: 115220.46, batch: 1
//
// naive: 240570.09090909088
// optimized: 225504.0909090909
Plans can also be shown nicely in a terminal with ANSI colors: